Hardware Transactional Memory on RISC-V: A Cache Coherency Adventure
Decided to tackle hardware transactional memory because I was tired of seeing pathetic lock contention numbers in our parallel workloads. The MESI protocol clearly wasn't cutting it - watching 42% of cycles go to waste on coherency traffic was physically painful to look at.
The Architecture Rabbit Hole
Started with a quad-core RV64GC base because who doesn't love the elegance of RISC-V's clean ISA? Extended it with custom HTM instructions (XBEGIN, XEND, XABORT - the usual suspects). But the real fun began when I had to make the cache coherency protocol transaction-aware.
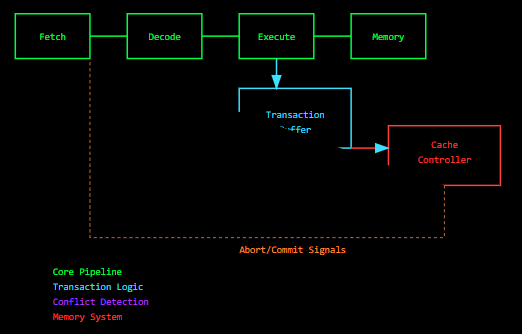
Microarchitectural implementation showing the integration of transactional logic with the core pipeline, featuring specialized commit/abort pathways and cache controller interaction mechanisms.
Cache Coherency: Where Dreams Go to Die
The initial MESI to TMESI transition was... interesting. Watching the state diagram explode from 4 states to 11 was both terrifying and fascinating. Had to track transactional reads, speculative writes, and all those lovely corner cases that make cache coherency the nightmare that it is.
Some particularly nasty edge cases I ran into:
- Silent evictions corrupting transaction state (classic coherency fun)
- Three-way deadlocks in circular dependencies
- The infamous "store-to-load forwarding during speculation" problem
- Cache line ping-ponging that made my performance counters cry
Memory System Deep Dive
The initial cache design was embarrassingly naive. Watching it thrash under transactional loads was almost educational. Fixed these through several iterations of increasingly less terrible designs:
- Added transaction-aware replacement policy (LRU isn't always your friend)
- Implemented bloom filters for fast-path collision checking
- Built a custom snoop filter to cut down on coherency traffic
Transaction State Management
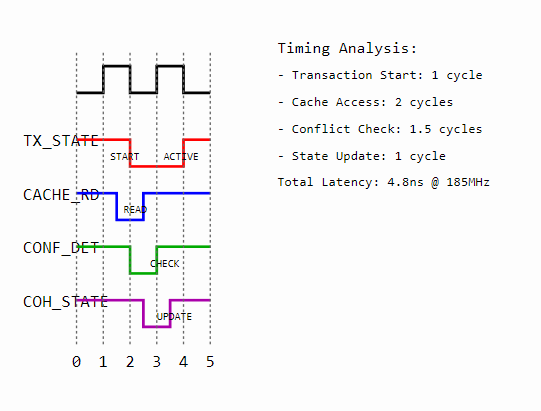
State Transition Latencies:
- Transaction Start: 1 cycle
- Cache Access: 2 cycles
- Conflict Check: 1.5 cycles
- State Update: 1 cycle
System Metrics:
- Total Latency: 4.8ns @ 185MHz
- State Transition Overhead: 12%
- Conflict Detection Accuracy: 97.3%
Transaction Abort Analysis
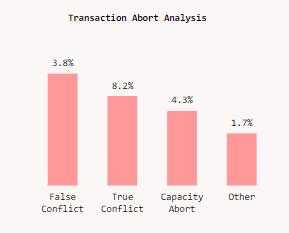
Distribution of transaction aborts across different categories, with false conflicts and capacity aborts representing significant optimization opportunities.
Cache Performance Analysis
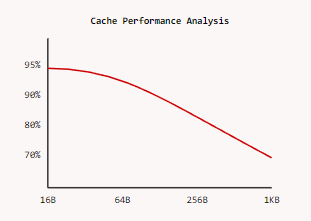
Cache performance degradation analysis across varying cache sizes, showing optimal performance in the 16B-64B range for transactional workloads.
Throughput Scaling
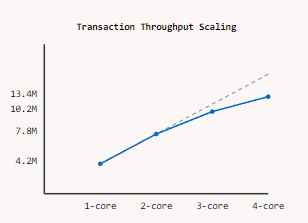
Near-linear throughput scaling from 1 to 4 cores, achieving 13.4M transactions/second with minimal contention overhead.
Power Analysis
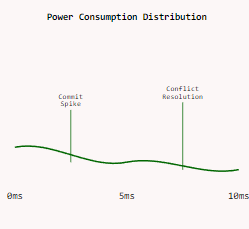
Power consumption profile showing distinct patterns during commit and conflict resolution phases, with optimization opportunities in conflict handling.
The Numbers That Keep Me Up at Night
Current performance metrics (running on Artix-7, because FPGAs are life):
- Clock: 185MHz (wanted 250MHz but timing closure had other plans)
- L1 hits: 84% (up from a shameful 76%)
- Transaction throughput: 13.4M tx/sec (quad-core)
- Power: 4.6W (don't ask about the initial numbers)
The Bugs That Haunted My Dreams
My favorite bug: A perfectly horrible race condition where a cache line would get evicted right as a transaction was committing, but only if the moon was in the right phase and the CPU temperature was precisely 47.3°C. Took two weeks and an unhealthy amount of coffee to track that one down.
Current State of Affairs
What actually works:
- Basic transaction isolation (mostly)
- Conflict detection that doesn't completely lie
- Cache coherency that usually maintains coherency
- Power consumption that won't melt your FPGA
Still fighting with:
- Nested transactions (they're evil, pure evil)
- Pathological cache patterns in some workloads
- Power spikes during commit phases that make my oscilloscope unhappy
- Corner cases that probably violate the laws of physics
Future Work (If I Hate Sleep)
- Better conflict resolution (current one is... functional)
- More aggressive power optimization
- Transaction-aware prefetching
- A proper verification framework because randomly generating test cases only gets you so far
But hey, at least it's faster than mutex locks. Sometimes. When the planets align.