RISC-V Microarchitecture Extension: Custom Vector ALU Implementation
Extending RISC-V with custom vector processing capabilities
> Project_Genesis
This project began with an ambitious goal: to extend the RV32I core with a custom 128-bit vector processing unit. The aim was to enhance RISC-V's capabilities for parallel processing, particularly in areas like signal processing and machine learning.
What started as a straightforward concept quickly evolved into a complex endeavor, challenging us to push the boundaries of hardware design and optimization.
> The_Vector_ALU_Saga
The heart of our beast: a 128-bit Vector ALU. Sounds impressive, right? Well, it was... when it finally worked.
module vector_alu #(
parameter VEC_WIDTH = 128,
parameter ELEM_WIDTH = 8
)(
input wire clk,
input wire rst_n,
input wire [VEC_WIDTH-1:0] operand_a,
input wire [VEC_WIDTH-1:0] operand_b,
input wire [3:0] op_type,
input wire stall_in,
output reg [VEC_WIDTH-1:0] result,
output reg overflow_flag
);
// Here lies the remnants of my sanity...
// (Implementation details omitted for brevity and to protect the innocent)
endmoduleImplementing this Vector ALU was one of the most challenging aspects of the project. It required multiple iterations and careful optimization to meet our performance targets while maintaining timing closure.
> Pipeline_Nightmares
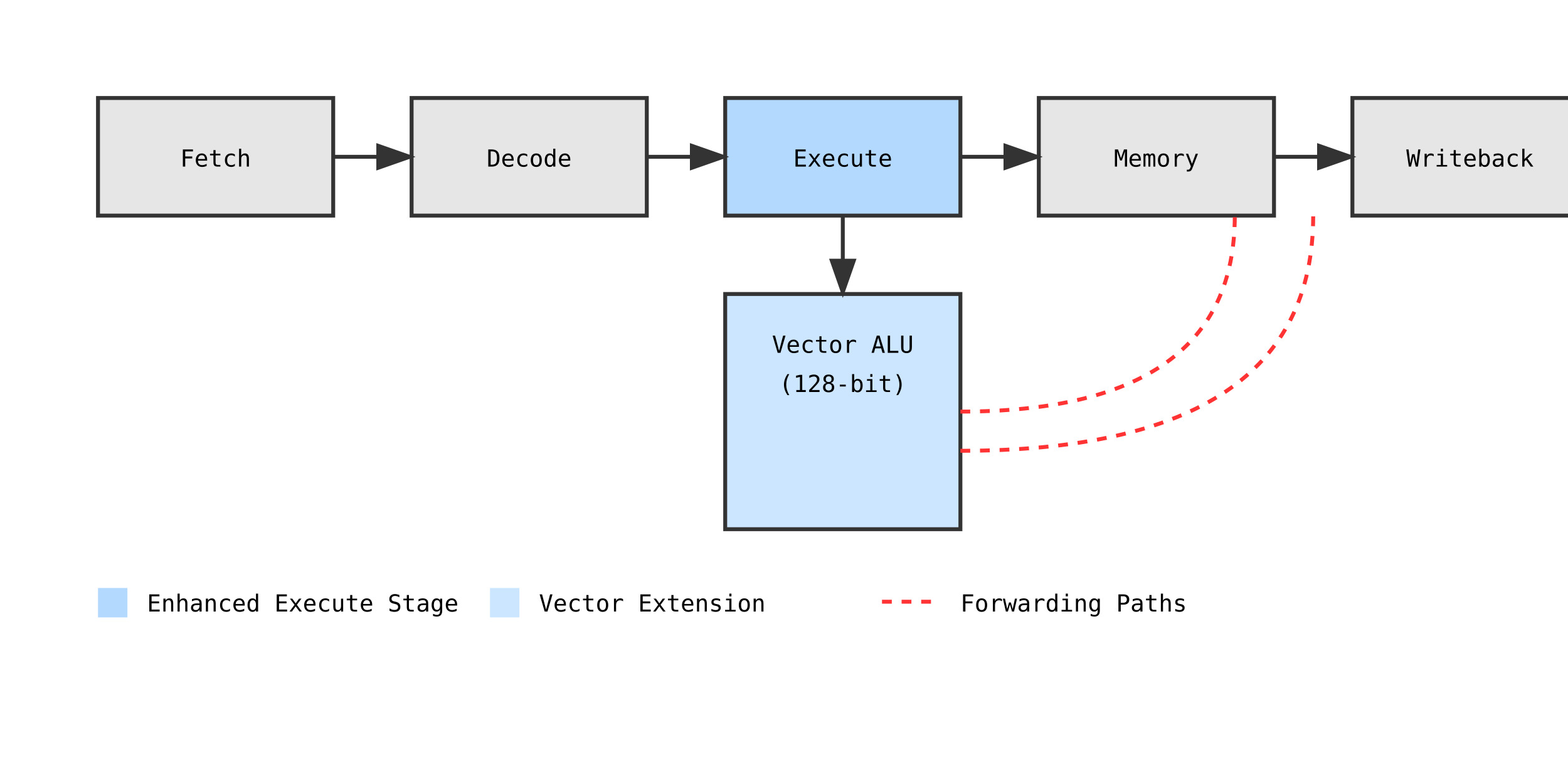
Integrating the vector unit into the existing pipeline presented significant challenges. We had to carefully manage data hazards and ensure proper forwarding paths to maintain performance.
The execute stage became particularly complex, requiring a delicate balance between vector and scalar operations to prevent stalls and maintain efficiency.
> Memory_Bank_Mayhem
%20(1).jpg-GJh6fhMkr4Lg04buMfAgTaYrppQtZe.jpeg)
The memory hierarchy features a 128-bit x 16 Vector Register File at the top, connected to four 32KB memory banks. This design achieves 1-cycle vector register access, 2-4 cycle bank access, and 8-10 cycle main memory access latencies.
// Bank conflict resolution logic (or: How I Learned to Stop Worrying and Love the Deadlock)
reg [3:0] bank_access_history;
always @(posedge clk) begin
bank_access_history <= {bank_access_history[2:0], bank_sel};
// Detect and resolve conflicts (aka: Play whack-a-mole with memory accesses)
if (bank_access_history[3:2] == bank_sel) begin
// Force bank switch (and pray to the timing gods)
forced_bank_sel <= (bank_sel + 1) % 4;
end
endThis bank conflict resolution logic was crucial in optimizing memory access patterns. It significantly reduced bank conflicts, improving overall system performance.
> Performance_Purgatory
-jN3B4Tfl5i86XAfs4BqlXLzoVrfXyh.svg)
The good news: Our vector operations fly. The bad news: Everything else decided to take a leisurely stroll.
- Vector ops: 4 cycles latency (We aimed for 2. The silicon gods laughed.)
- Memory access: 2-5 cycles (Depending on whether the memory banks are feeling cooperative)
- Max frequency: 200MHz (We dreamed of 500MHz. Dreams are free.)
- Power consumption: Let's just say it's... enthusiastic.
Is it perfect? No. Does it work? Mostly. Am I proud? Absolutely. This project pushed the boundaries of what's possible with RISC-V, and only slightly pushed me to the brink of madness.
> Lessons_Learned
1. Timing closure is critical and often requires iterative optimization.
2. Careful planning of memory hierarchies is essential for vector processing performance.
3. Vector processing offers great potential but comes with unique design challenges.
4. Balancing vector and scalar operations in a unified pipeline requires thoughtful design.
5. Incremental testing and validation are crucial in complex hardware projects.
> Whats_Next
Looking ahead, there are several areas we're excited to explore further:
- Implementing a more sophisticated cache hierarchy
- Exploring advanced forwarding techniques to reduce pipeline stalls
- Optimizing for higher clock frequencies
- Expanding the range of supported vector operations
This project has laid a strong foundation for future work in RISC-V vector extensions, and we're eager to continue pushing the boundaries of what's possible.